FILE Job
Overview
The FILE job provides a way to retrieve CSV files from remote servers and upload them into ATSD on schedule.
In addition, it supports downloading JSON files and converting them to CSV format.
Other than the JSON to CSV conversion, the FILE job doesn't make any changes to the downloaded files and doesn't perform any local parsing.
The files are parsed by ATSD using a CSV Parser that is configured with the specific file format in mind.
Workflow
- Download the file from a remote server or read it from the local file system.
- Validate the file format.
- CSV: check line count and match text in the first line.
- JSON: check that the format is JSON and that the file contains the specified text.
- In case of JSON, convert the JSON document to a tabular CSV format.
- Upload the CSV file to ATSD for parsing.
- Copy the file to a
successorerrordirectory based on the ATSD response status. - Repeat steps 1-to-5 if the Path is configured to download multiple files with an
ITEMfrom the item list, theDATE_ITEMfunction, or a wildcard expression in the case of FILE, FTP, and SFTP protocols. - Send a job status message into ATSD for monitoring.
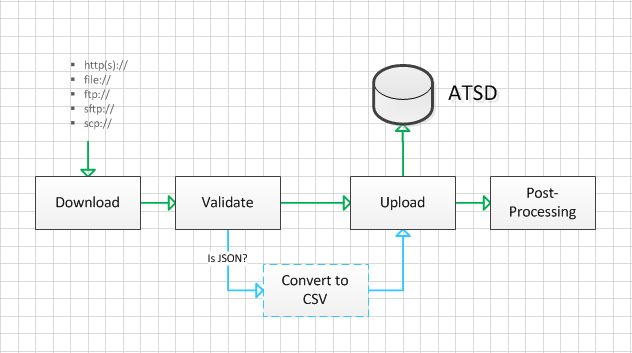
Supported Protocols
| Protocol | Scheme | Wildcards | Description |
|---|---|---|---|
| FILE | file:// | yes | Read file(s) from the local file system./tmp/report/daily*.csv |
| HTTP | http(s):// | no | Download a file from a web server.https://example.com/traffic/direct.csv |
| HTTP_POOL | http(s):// | no | Download a file from a web server using pre-configured HTTP pool./traffic/direct.csv |
| FTP | ftp:// | yes | Download file(s) from an FTP server.ftp://example.com/data/CCE2_121W_*.csv |
| SFTP | sftp:// | yes | Download file(s) from a UNIX server over STFP protocol.sftp://ftp-reader:my-pwd@10.52.0.10:22/home/ftp-reader/*.csv |
| SCP | scp:// | no | Download a file from a UNIX server over SCP protocol.scp://user-1:my-pwd@example.com:4022/home/user-1/r20160617.csv |
File Watch
In addition to scheduled checks, the FILE protocol exposes a setting to continuously watch the target path(s) for file creation and modification events.
When the file in the watched directory is created or changed, it is processed with the same workflow as files identified with the scheduled execution, except that the job continues running and watching for subsequent changes until the next job start time or until the watch interval expires.
Tests of file watch configurations are pre-configured to watch the directory for 15 seconds.
Consecutive file modification events that occurred within 1 second of each other are deduplicated to prevent too many files being sent into the database.
Note that watch monitors only file create and modify events. Existing files that match the path but remain unchanged will be ignored.
Downloading Multiple Files
To download multiple files with the same configuration, utilize one of the following options:
- Match multiple files with a
*or?wildcard in the Path, provided the protocol supports wildcards. - Create a collection of items, referred to as
item list, and include an${ITEM}placeholder in the Path.
The configuration will be repeated for all elements in the list.
The item list can be defined manually or can be retrieved from an external source such as a script.
The item list can include parts of the Path or the entire Path. - Include
${DATE_ITEM()}function in the Path. The${DATE_ITEM()}function produces an array of dates between start and end time, formatted with the specified pattern. The configuration will be repeated for all dates returned by the functions.
Wildcard examples for FILE protocol:
/home/axibase/daily/*/*/packag?/report*.csv
/home/axibase/daily/*/*/packag?/${ITEM}.json
/tmp/collector/errors/*.json
/tmp/collector/errors/${TIME("previous_day", "yyyy-MM-dd")}/downloaded*.csv
FILE protocol supports directory traversal.
Configuration
Download
| Name | Description |
|---|---|
| File Format | CSV or JSON. JSON files are converted into CSV files prior to uploading. |
| Protocol | Network or file protocol to download the file from a remote server or read it from the local file system. |
| Path | URI to the data file in RFC 3986 form: [user:password@]host[:port][/]path[?query][#fragment].Example: https://example.com/traffic/direct.csv.If HTTP_POOL is selected, the URI should be relative: /path[?query][#fragment].If the FILE protocol is selected, the Path to files on the local file system should be absolute.Supported placeholders: ${ITEM}, ${TIME()}, ${DATE_ITEM()}. |
| Item List | A collection of elements to execute multiple file requests in a loop. The current element in the loop can be accessed with the ${ITEM} placeholder, which can be embedded into the Path and Default Entity fields.When Item List is selected and ${ITEM} is present in the Path, the job will execute as many queries as there are elements in the list, substituting ${ITEM} with an element value for each request.${ITEM} value can be url-encoded as follows: ${ITEM?url} |
HTTP-specific Download Settings
| Name | Description |
|---|---|
| HTTP Pool | Pre-defined HTTP connection parameters with optional authentication credentials and custom network/connection settings. |
| HTTP Method | HTTP method executed: GET or POST. POST method provides a way to specify request headers and payload parameters. |
| Payload | POST method payload. |
| Headers | HTTP request headers. |
| Enable Web Driver | Executes Web Driver Script to download the file. |
| Driver Script | Downloads the file by executing pre-recorded browser actions such as opening a page and clicking on a button to export a file. The script can be recorded in Selenium IDE and exported into Java format. |
| Driver File Encoding | File Encoding to use when saving the file downloaded with script. |
| Driver Timeout | Maximum time, in seconds, allowed for the script to run before timeout. |
FILE-specific Download Settings
| Name | Description |
|---|---|
| Watch Enabled | Watch the target directories for file creations and modification and process the file on change event without a delay. |
| Watch Interval | If set, the target directories will be watched for changes for the specified number of seconds. If omitted or set to 0, the target paths will be watched for changes until the next job start time. |
Watched directories must exist at the time the job is executed. Changes in the directory that were deleted and re-created during the job execution will not be visible to the job until it is restarted.
Validate
| Name | Format | Description |
|---|---|---|
| Minimum Line Count | CSV | Minimum line count for the CSV file to contain. An error will be raised if the threshold is greater than 0 and the number of lines in the file is less than the threshold. |
| First Line Contains | CSV | Checks if the first non-empty line in the file contains the specified text. The check is case-sensitive. If the specified text is not found within the first non-empty line, the data will not be sent to ATSD. Supported placeholders: ${ITEM}`, `${TIME()}`, `${FILE}`, `${DIRECTORY}`, `${PATH}. For example: # Effective Data ${TIME("previous_day", "dd.MM.yyyy")}. |
| File Contains | JSON | Checks if the file contains the specified text on any line. The check is case-sensitive. If the specified text is not found within the file text, the data will not be sent to ATSD. Supported placeholders: ${TIME}. For example: "report_date": "${TIME("current_day", "yy/MM/dd")}". |
| Parse | JSON | JSON files are automatically validated by parsing the file as a JSON document. |
Convert to CSV
- Conversion settings are applicable to JSON files.
| Name | Description |
|---|---|
| JSON Path | JSON Path expression to match an object or a list of objects in the JSON document. Default path is $, which stands for the root object.The collector will attempt to convert fields of the matched objects to a tabular structure, using field names as column names and field values as cell values. For fields in the nested objects, column names are formed by concatenating parent object names using dot notation. Each matched objects returned by the JSON path expression will be represented as a separate line in a CSV file. |
| Traversal Depth | Limit traversal of the matched object(s). If Depth is set to a positive number, nested objects are included in the CSV files up to their depth level measured as the distance between the nested object and the matched object. When Depth is set to 1, the collector will include only direct fields of the matched objects. If Depth is set to 0 or a negative number, all nested objects will be traversed and included into the CSV files. |
| Included Fields | By default, all fields with primitive data types (number, string, boolean) are included in the CSV file. Array fields are ignored. The list of included fields can be overridden explicitly by specifying particular field names, separated by comma. |
| Excluded Fields | List of field names to be excluded from the CSV file. Applies if Included Fields is empty. |
Upload
| Name | Description |
|---|---|
| Parser Name | CSV Parser name for parsing the uploaded CSV file. The parser can be created on the Configuration: Parser CSV page in ATSD. The parser should exist and be enabled. |
| Auto Detect Encoding | Automatically detect the file's charset based on its leading bytes, the header, and the heuristics. The detected charset will be submitted to ATSD so that the file can be correctly parsed by the database. |
| Encoding | Specify the file's charset. The charset will be submitted to ATSD so that the file can be correctly parsed by the database. |
| Metric Prefix | Text added to all metrics names extracted from the CSV file, typically to column headers. For example, if the Metric Prefix is set to custom., and the file contains the 'PageViews' column, the resulting metric name will be custom.Pageviews. |
| Default Entity | Default Entity name to use if the file doesn't contain information about the entity name. The Default Entity name may include placeholders, such as ${ITEM}, which will be substituted by an element value when the Item List is selected. Supported placeholders are: ${ITEM}, ${FILE}, ${PATH}, ${DIRECTORY}, ${TIME()}. |
| Custom Tags | List of name=value tag pairs, one per line. The tags will be stored by the database as additional series/property/message tags.Supported placeholders are: ${ITEM}, ${FILE}, ${PATH}, ${DIRECTORY}, ${TIME()}. |
| Use Current Time | Enables all data contained in the CSV file to be stored with the current time of the Collector instead of the date/time possibly contained in the file. This option should be used when the CSV file doesn't contain any time/date information. |
| Time Zone | Time Zone which should be used by ATSD when parsing the datetime column in the CSV file, if the datetime format does not contain information about the time zone. |
| Wait for Upload | Wait for ATSD to finish validating and parsing the uploaded file. If disabled, the server responds HTTP Code 200 (success) immediately after the file is transferred to ATSD. If Wait for Upload is disabled, the collector job may not know if the upload file is valid and if it contains any errors. |
| Process in Rule Engine | Process parsed commands in the ATSD Rule Engine. If enabled, allows the data in the CSV file to be checked by rules. |
| Ignore Unchanged Files | Prevents unchanged files from being repeatedly uploaded into the database. When enabled, the collector compares the downloaded file's last modified time (FILE, FTP, SFTP) or MD5 hashcode (HTTP, HTTP_POOL, SCP) with the previously stored information and ignores the upload if the file hasn't changed. For FTP and SFTP protocols, the remote files with unchanged last modified times are not downloaded to the collector host. |
Post-Processing
| Name | Description |
|---|---|
| Delete Files on Upload | Applies to FILE protocol. Delete source files that were successfully uploaded into the database. |
| Copy Files | Copy downloaded file(s) into a Success or Error directory based on a local or remote status code. For example, if the file failed during validation, it will be copied to the Error directory. |
| Success Directory | Absolute path to a directory for storing successfully uploaded files. If the directory is specified but does not exist, it will be created. Supported placeholders: ${ITEM}, ${TIME()}. |
| Error Directory | Absolute path to a directory for storing a file that failed to get uploaded successfully for any reason. If the directory is specified but does not exist, it will be created. Supported placeholders: ${ITEM}, ${TIME()}. |
Placeholders
| Name | Description |
|---|---|
${ITEM} | Current element in the Item List. |
${TIME()} | Text output of the TIME function. |
${DATE_ITEM()} | Current element in the Date Item List. |
${PATH} | URL path or the file's absolute path. |
${FILE} | Name of the downloaded file. |
${DIRECTORY} | Parent directory of the downloaded file. |
Refer to placeholder examples.
Examples
- duckduckgo.com Search Statistics
- Sunspot Daily Count
- nginx Web Server Basic Statistics
- Australian Bureau of Meteorology: JSON
- Energinet DK Market Data
- pvoutput.org Solar System Statistics
- Stackoverflow Tags: JSON
- UK Civil Aviation Authority
- airnow.gov Climate and Pollution Statistics
- National Oceanic and Atmospheric Administration (NOAA) Mooring Data
- Yahoo! Finance Daily Quotes